Distributed latency monitoring
For a while, I have been looking for a smokeping alternative for latency monitoring from different servers spread around. While smokeping has survived well over time, in 2023 it feels like an outdated package, with limited options, lacks federation etc. This post from Karan Sharma / Zerodha on “Monitoring my home network” was exciting. His setup included a telegraph agent on a local server, Prometheus to scrap data and Grafana to draw latency data. I explored doing the same but in a distributed manner a bunch of servers spread around. After some tries, I didn’t like Telegraf. Don’t get me wrong - it’s a good “agent” to run on Linux servers but is primarily designed assuming push target against a time series database like InfluxDB which created it. I am still exploring using it for a different use case (which is pulling SNMP data from switches).
Blackbox Exporter
For latency, I settled for Blackbox exporter. It’s again an open-source tool which can run as a container or a service on a Linux machine. Single binary which just needs a config file and one is good to go. Besides ICMP, it can also do HTTP(s), DNS, TCP and gRPC monitoring which makes it a handy agent. I have a use case where I want a native install instead of a docker on most servers because all servers do not have a docker engine. But at the same time, I need docker at home on Intel NUC because that way I can run two instances of Blackbox exporter across two different containers which are routed behind each ISP at home using policy-based routing.
Another thing I liked about Blackbox Exporter is the config style. It takes only the probe config but actual measurement targets are provided in the Prometheus configuration. This gives me the option to have a single Prometheus config with all the targets for all the servers.
Here’s my setup for now:
- Blackbox exporter - To trigger measurement
- Prometheus (it holds targets which are provided during the scrapping of data)
- Grafana to plot it
- Alert Manager to trigger alerts for high latency
This is a pretty powerful and scalable setup. With a couple more things like backing up older metrics on a s3 endpoint, one can scale it up easily. Plus Blackbox exporter with config is effectively a stateless container and thus besides hosting it on my infra I can also host it on Google Cloud run and that gives me instant distributed view/latency/HTTP checks from Google against my infrastructure without having to host an expensive server over there.
Here’s an example GET call to a Blackbox exporter endpoint to check for “anuragbhatia.com”
anurag@desktop ~> curl -s 'lo.host01.bom.anuragbhatia.com:9115/probe?target=anuragbhatia.com&module=icmp4'
# HELP probe_dns_lookup_time_seconds Returns the time taken for probe dns lookup in seconds
# TYPE probe_dns_lookup_time_seconds gauge
probe_dns_lookup_time_seconds 0.130653477
# HELP probe_duration_seconds Returns how long the probe took to complete in seconds
# TYPE probe_duration_seconds gauge
probe_duration_seconds 0.132437039
# HELP probe_icmp_duration_seconds Duration of icmp request by phase
# TYPE probe_icmp_duration_seconds gauge
probe_icmp_duration_seconds{phase="resolve"} 0.130653477
probe_icmp_duration_seconds{phase="rtt"} 0.001477566
probe_icmp_duration_seconds{phase="setup"} 0.000116058
# HELP probe_icmp_reply_hop_limit Replied packet hop limit (TTL for ipv4)
# TYPE probe_icmp_reply_hop_limit gauge
probe_icmp_reply_hop_limit 62
# HELP probe_ip_addr_hash Specifies the hash of IP address. It's useful to detect if the IP address changes.
# TYPE probe_ip_addr_hash gauge
probe_ip_addr_hash 8.53196068e+08
# HELP probe_ip_protocol Specifies whether probe ip protocol is IP4 or IP6
# TYPE probe_ip_protocol gauge
probe_ip_protocol 4
# HELP probe_success Displays whether or not the probe was a success
# TYPE probe_success gauge
probe_success 1
anurag@desktop ~>
probe_icmp_duration_seconds{phase="rtt"} 0.001477566 here tells the RTT (Round Trip Time).
Here’s a sample job config for Prometheus:
- job_name: host01.bom.anuragbhatia.com-blackbox-icmp4 # To get metrics about the exporter’s targets
metrics_path: /probe
scrape_interval: 60s
params:
module: [icmp4]
static_configs:
- targets:
# Europe
- speedtestmera.vs.mythic-beasts.com #London
- nbg.icmp.hetzner.com # Hetzner Nuremberg
- fsn.icmp.hetzner.com # Hetzner Falkenstein
- hel.icmp.hetzner.com # Hetzner Helsinki
- s3.fr-par.scw.cloud # Scaleway Paris
- s3.nl-ams.scw.cloud # Scaleway Amsterdam
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: lo.host01.bom.anuragbhatia.com:9115
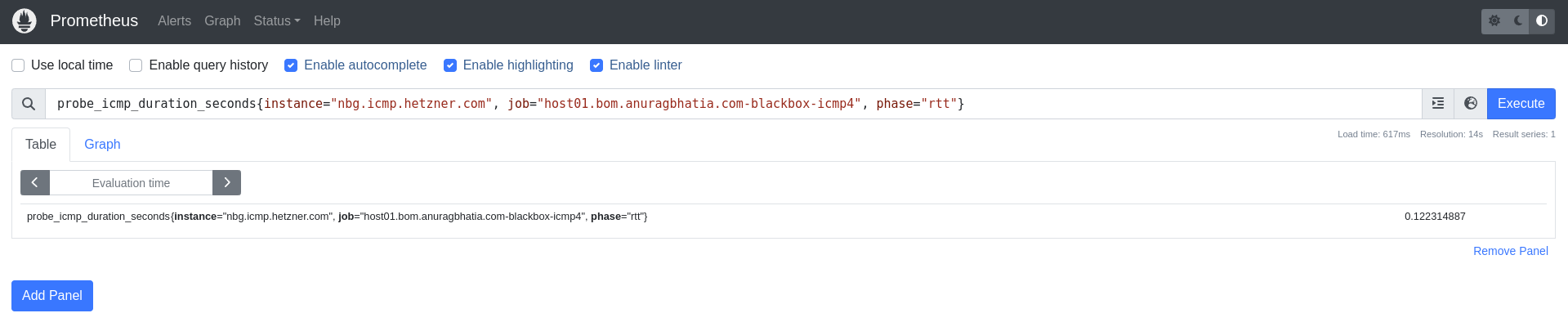
This triggers measurement against these targets every 60 seconds. Here’s a view of data from Prometheus’s time series database say for Hetzner Nuremberg:
Next, the same can be used in Grafana connected to this Prometheus instance to graph:
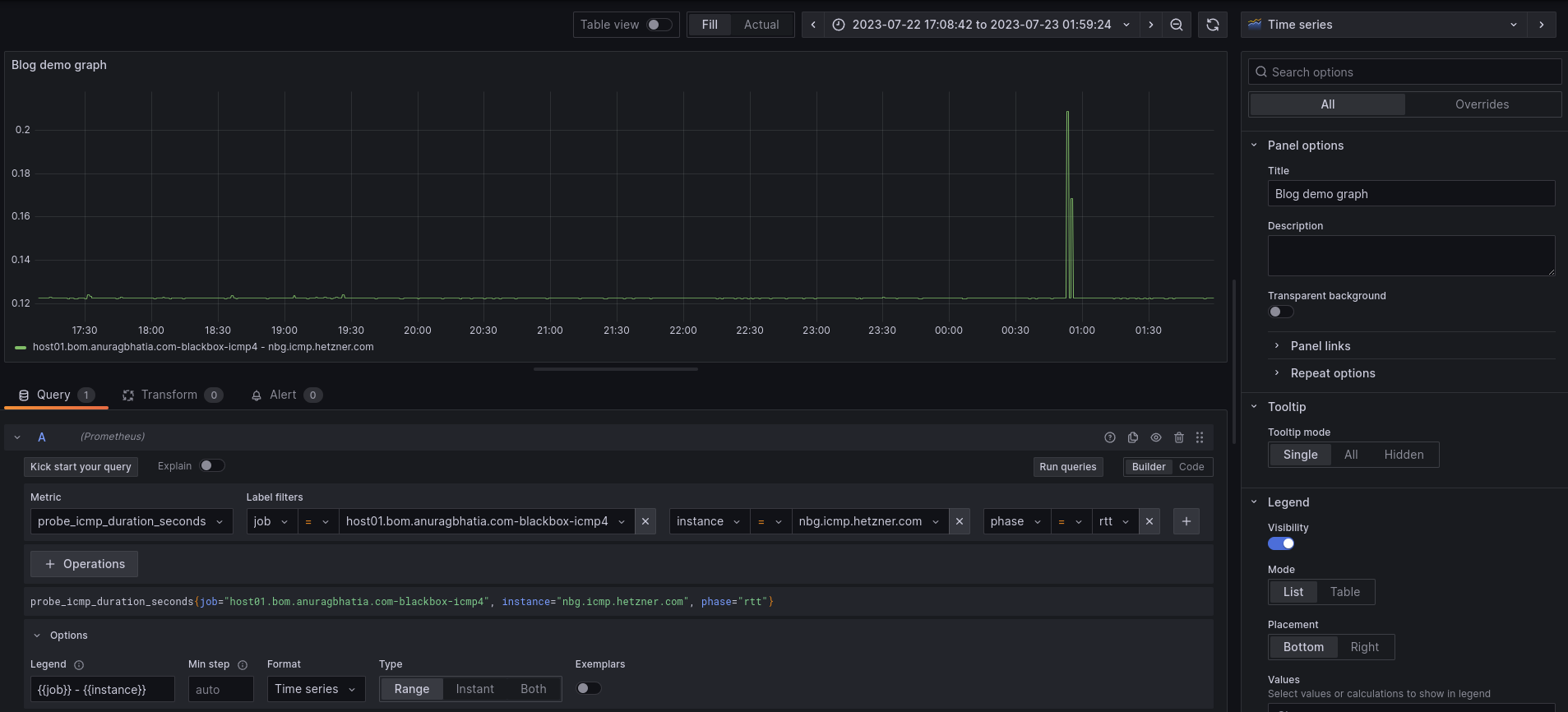
One can remove instance matching here to get all instances in the single graph which seems like a powerful way to analyse latency to all destinations in a single graph.
While I started with replacing smokeping. I think with this setup, I can also replace LibreNMS and Uptime-Kuma as well. So far I am loving the simplicity and power of Prometheus. It’s a work in progress for now. Also got to add IPv6 probes before migrating away from Smokeping.
Off for the weekend!