Welcome to India Vultr!
Vultr has announced start of their Mumbai location on 12th of this month. It’s amazing to see them entering India. Always a good thing for growth of cloud computing on demand in India.
Besides Vultr, we have got Amazon AWS, Microsoft Azure, Google Cloud, Digital Ocean, Linode, Oracle Cloud etc in India. I heard OVH also planning for Indian location and so have to see how that goes.
In meanwhile, let’s have a quick check on Vultr’s network connectivity. I just created a Virtual machine in Mumbai to look at the routing and connectivity. I got following for my test VM:
IPv4: 65.20.72.4
IPv6: 2401:c080:2400:15fb:5400:03ff:fef3:0b95
ASN originating these pools: 20473
IP transit check
IPv4 pool is part of 65.20.64.0/19 BGP announcement and is Tata Communications AS4755 and Bharti Airtel AS9498. Peeringdb hints that Vultr is at Equinix GPX MB 2.
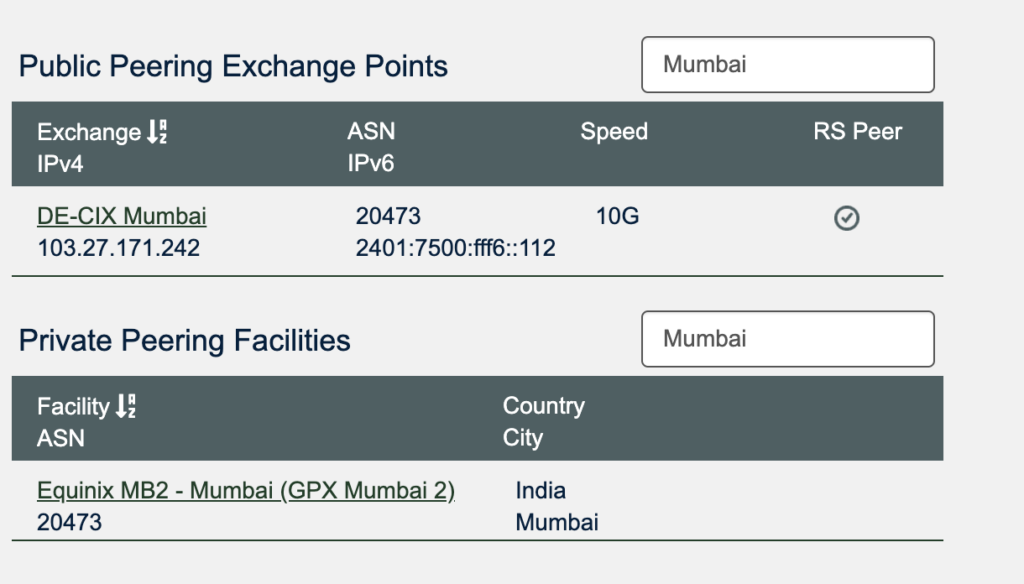
Location & Peering
It’s the newer Equinix GPX datacenter. I happen to visit that last month. They also seem to be live at DECIX Mumbai IX. I see a direct peering route from my server on CTPL AS132933 network via DECIX.
traceroute to 65.20.72.4 (65.20.72.4), 30 hops max, 60 byte packets
1 10.51.0.1 (10.51.0.1) 0.174 ms 0.137 ms 0.123 ms
2 ctpl-demarc.bom.anuragbhatia.com (45.64.190.61) 1.271 ms 1.255 ms 1.276 ms
3 **103.27.171.242** (103.27.171.242) 0.613 ms 0.581 ms 0.565 ms
4 10.90.0.6 (10.90.0.6) 1.037 ms 1.407 ms 1.388 ms
5 10.90.0.138 (10.90.0.138) 0.428 ms 10.90.0.130 (10.90.0.130) 0.410 ms 0.430 ms
6 * * *
7 * * *
8 * * *
From Indian RIPE Atlas probes, they seem to be within max of 69ms latency. Here’s a measurement I just triggered for IPv4 and this one for IPv6. For routing towards Jio it seems like a mix of both Airtel and Tata Comm. I see Vultr -> Jio via Airtel on IPv4 and via Tata Comm incase of IPv6.
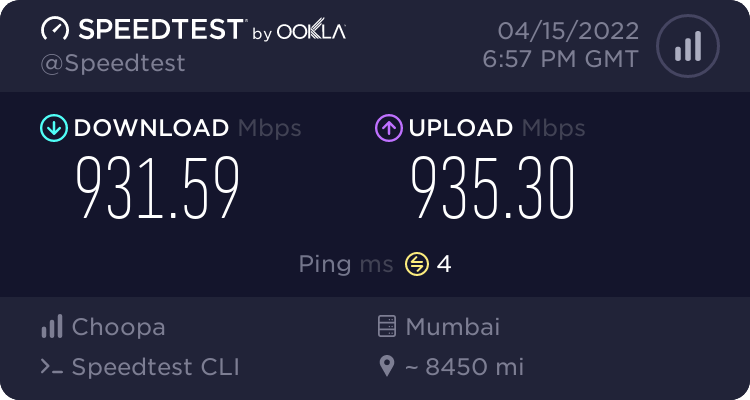
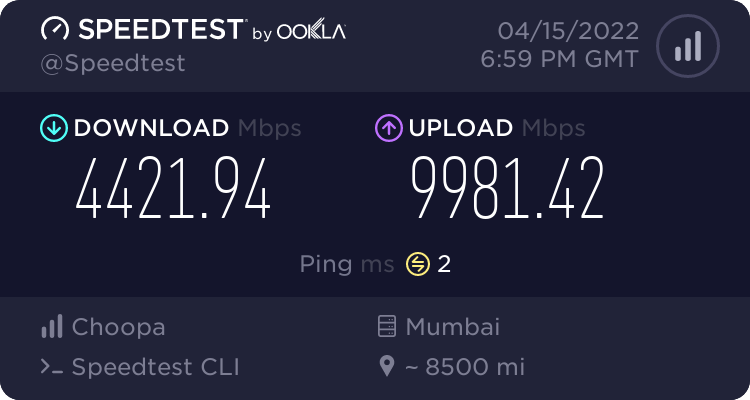
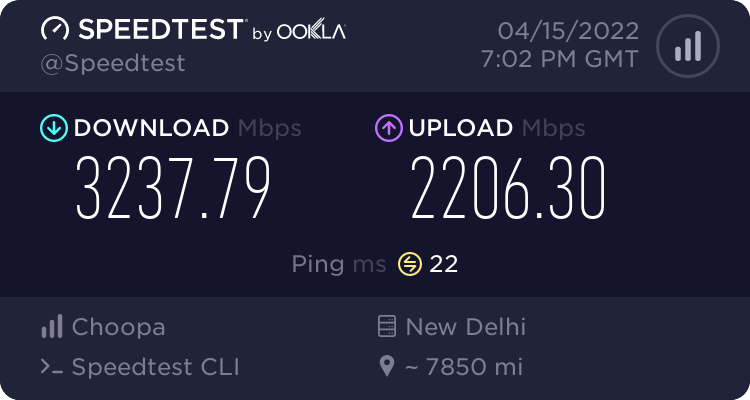
Speedtest
I ran speedtest against a few targets using speedtest-cli docker image.
Speedtest by Ookla
Server: Tata Play Fiber - Mumbai (id = 23647)
ISP: Choopa, LLC
Latency: 1.41 ms (0.15 ms jitter)
Download: 3582.64 Mbps (data used: 3.8 GB )
Upload: 6964.89 Mbps (data used: 8.3 GB )
Packet Loss: 0.0%
VI Mumbai
Jio Mumbai
Excitel Delhi
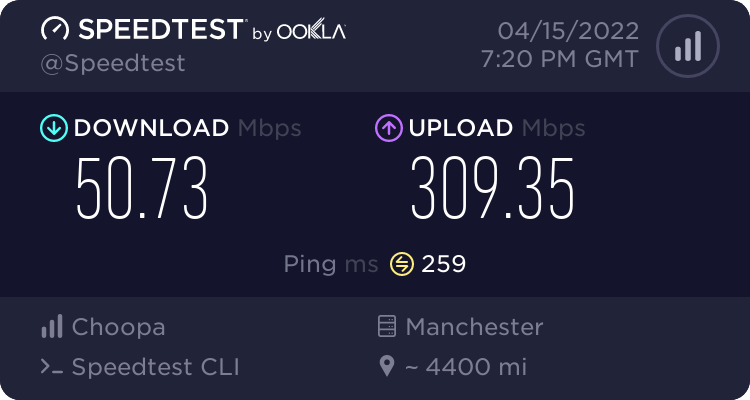
Vodafone UK
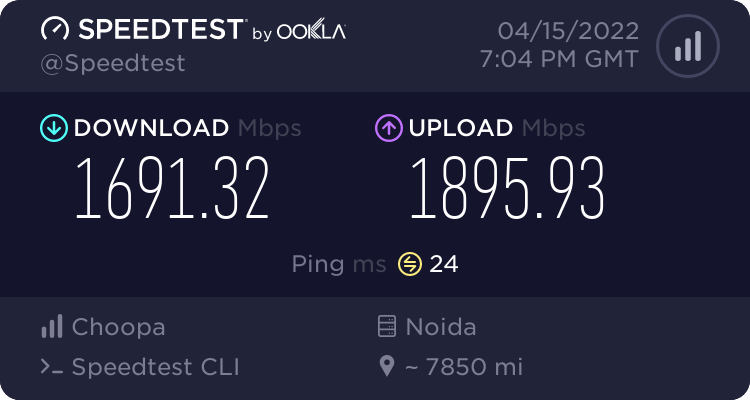
Airtel Delhi

ACT Delhi
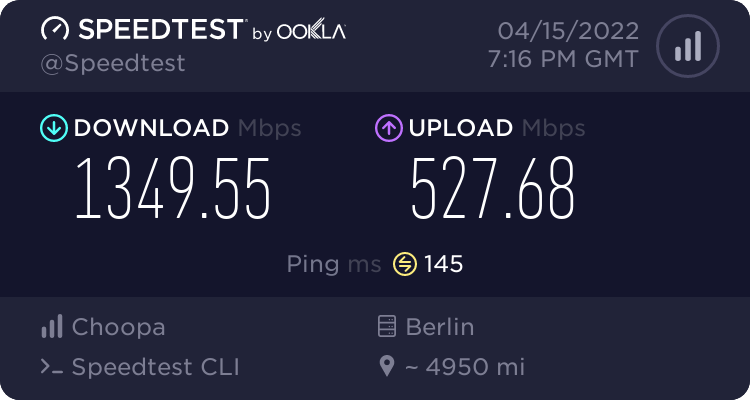
Telekom Germany
So speeds are pretty impressive. It’s 10G port giving 3-4Gbps in most of the cases. VI Mumbai seems to be limiting at 1Gbps and I guess it’s due to VI using GigE port on their server. This test was done on $6/month ….$0.009/hour VM - the cheapest I could get to test and used around 40GB worth of transfers in this testing.
root@test02:~# ifconfig enp1s0 | grep "X packets"
RX packets 27512654 bytes 36802178242 (36.8 GB)
TX packets 2413882 bytes 47519479160 (47.5 GB)
root@test02:~#
IPv6 on Vultr
Vultr gives a full /64 IPv6 per VM which is great but the pool is not routed. What that means is that IPv6 works only when the address is added on the interface as it gets in the NDP table to enable Vultr to route. This not ideal and makes it challenging to utilise IPv6 on anything running inside the VM say on a container.
How to check whether pool is routed or not?
Have a look at the allocation:
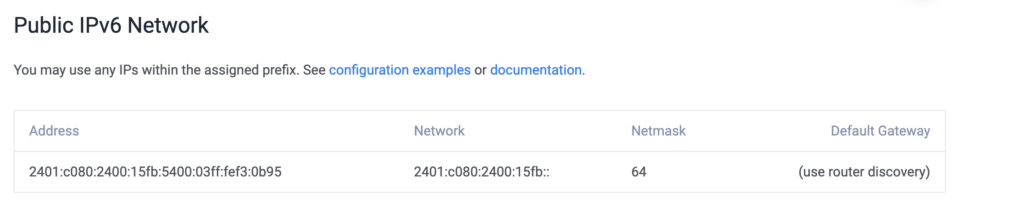
Telekom Germany
So that’s 2401:c080:2400:15fb::/64. Let’s pick any address inside it to test other than one which is already on interface. Say 2401:c080:2400:15fb::ab and ping it from outside network while looking at packets on the VM’s interface:
PING 2401:c080:2400:15fb::ab(2401:c080:2400:15fb::ab) 56 data bytes
From 2401:c080:2400:424::33 icmp_seq=1 Destination unreachable: Address unreachable
From 2401:c080:2400:424::33 icmp_seq=2 Destination unreachable: Address unreachable
From 2401:c080:2400:424::33 icmp_seq=3 Destination unreachable: Address unreachable
From 2401:c080:2400:424::33 icmp_seq=4 Destination unreachable: Address unreachable
From 2401:c080:2400:424::33 icmp_seq=5 Destination unreachable: Address unreachable
--- 2401:c080:2400:15fb::ab ping statistics ---
5 packets transmitted, 0 received, +5 errors, 100% packet loss, time 4088ms
This is fine and expected since IPv6 is not on any interface. Let’s look at the tcpdump:
root@test02:~# tcpdump -i enp1s0 'dst 2401:c080:2400:15fb::ab' -n
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on enp1s0, link-type EN10MB (Ethernet), capture size 262144 bytes
^C
0 packets captured
0 packets received by filter
0 packets dropped by kernel
root@test02:~#
Nothing. As soon as I add IPv6 on WAN interface it just works. Another way to test it can be by adding individual IPv6 as /128 on the loopback and see if it pings from outside. Essentially Vultr should be using layer 3 and routing 2401:c080:2400:15fb::/64 to the VM’s WAN IP.
What to do when pool is not routed?
Solution here is going to be ugly. One can use NDP proxy. That would simple listen for NDP requests coming on the WAN interface and would reply with proxy NDP if it finds DST address as per the definition in it’s config.
Thus except this IPv6 pool not routed issue (which is there across all their global locations), I find them quite good.