Inefficient IGP can make eBGP go wild!
Lately, I have been struggling to keep latency in check between my servers in India and Europe. Since Nov 2021 multiple submarine cables are down impacting significant capacity between Europe & India. The impact was largely on Airtel earlier but also happened on Tata Comm for a short duration. As of now Airtel is still routing traffic from Europe > India towards downstream networks via the Pacific route via EU > US East > US West > Singapore path. Anyways, this blog post is not about the submarine cable issue.
The issue at hand is IPv6 and IGP. One of my servers in Mumbai on Oracle Cloud has a high latency of 270ms with my server in Nuremberg, Germany
anurag@server02 ~> ping6 -c 5 server7.anuragbhatia.com
PING server7.anuragbhatia.com(server7.anuragbhatia.com (2a02:c207:2022:2769::1)) 56 data bytes
64 bytes from server7.anuragbhatia.com (2a02:c207:2022:2769::1): icmp\_seq=1 ttl=53 time=270 ms
64 bytes from server7.anuragbhatia.com (2a02:c207:2022:2769::1): icmp\_seq=2 ttl=53 time=271 ms
64 bytes from server7.anuragbhatia.com (2a02:c207:2022:2769::1): icmp\_seq=3 ttl=53 time=270 ms
64 bytes from server7.anuragbhatia.com (2a02:c207:2022:2769::1): icmp\_seq=4 ttl=53 time=270 ms
64 bytes from server7.anuragbhatia.com (2a02:c207:2022:2769::1): icmp\_seq=5 ttl=53 time=270 ms
--- server7.anuragbhatia.com ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4208ms
rtt min/avg/max/mdev = 270.487/270.493/270.509/0.008 ms
anurag@server02 ~>
Mumbai to most networks in the EU should be somewhere between 120ms to 160ms. Lowest in France & London due to location of submarine cable landing while highest as we go further East of Europe.
Traceroute: Mumbai, India -> Nuremberg, Germany
traceroute to server7.anuragbhatia.com (2a02:c207:2022:2769::1) from 2603:c021:4000:2401::b02, 30 hops max, 24 byte packets
1 2603:c000:500::8c5b:cc03 (2603:c000:500::8c5b:cc03) 0.3367 ms 0.3110 ms 0.4890 ms
2 2403:0:100::a9e (2403:0:100::a9e) 8.4735 ms 1.5194 ms 1.4376 ms
3 2403:0:100::a9d (2403:0:100::a9d) 1.9891 ms 1.8734 ms 1.6902 ms
4 2403::776 (2403::776) 2.0564 ms 2.2611 ms 2.0270 ms
5 if-ae-1-101.tcore2.mlv-mumbai.ipv6.as6453.net (2001:5a0:2300:300::1) 2.0844 ms 2.1834 ms 1.9478 ms
6 if-ae-16-2.tcore1.svw-singapore.ipv6.as6453.net (2405:2000:ffa0:100::76) 60.6122 ms 60.7606 ms 60.6986 ms
7 if-et-23-2.hcore2.kv8-chiba.ipv6.as6453.net (2405:2000:ffa0:100::73) 128.7493 ms 126.9237 ms 126.7353 ms
8 if-ae-53-2.tcore2.lvw-losangeles.ipv6.as6453.net (2001:5a0:fff0:100::24) 232.7306 ms 232.9346 ms 232.8798 ms
9 * * *
10 xe-8-1-0.edge1.miami.Level3.net (2001:1900:4:3::1d5) 233.1292 ms 233.5304 ms 233.0814 ms
11 * * *
12 GIGA-HOSTIN.edge8.Frankfurt1.Level3.net (2001:1900:5:2:2:0:c:49ee) 252.8902 ms 253.4336 ms 253.2449 ms
13 * * *
14 * * *
So this is: Mumbai > Singapore > Chiba (Japan) > Los Angeles > next, 9th hop isn’t visible but I can imagine it would be somewhere in the bay area …likely San Jose where handoff to Lumen/Level3 AS3356 happens. Next, Level3 carries it to Miami and finally to Frankfurt which is near to the destination Nuremberg. Due to the MPLS tunnel in Level3’s network, one cannot confirm the path but logically & latency wise it seems correct. The issue is why Tata Comm is even carrying these packets to the US and not to Europe directly?
The issue becomes more interesting because Tata Comm is handing off packets to one of the large IP backbones Lumen/Level3. Both are known to be transit free tier 1 networks and known to be peering in the US and Europe. In theory, it is possible (though unlikely) that all peering sessions between them went down in Europe & hence only “entry point” here is via Lumen PoP in the US. To rule out that, let’s look at the trace to the same destination via Tata Comm AS6453 Marseille, France PoP from their looking glass:
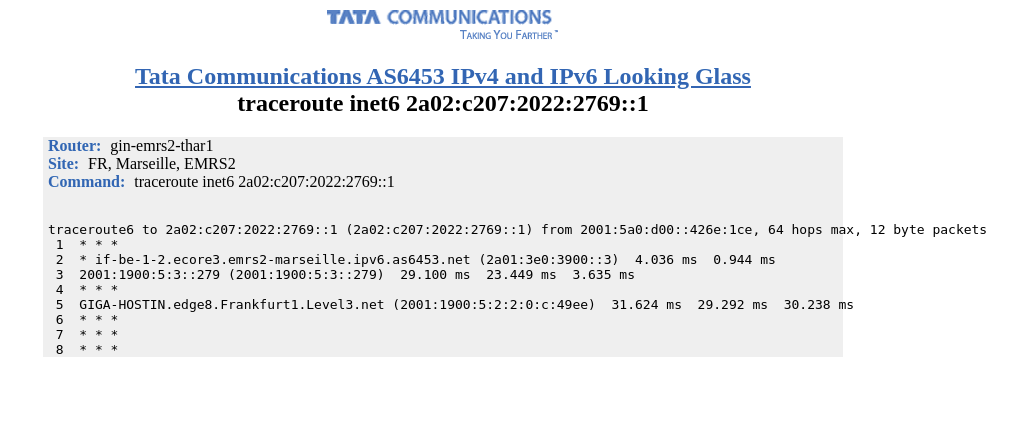
The route is direct. Hence this confirms that Tata Comm is indeed learning routes from Lumen in Europe including the one here in question.
So why do they route via the US in this case?
Let’s cross-validate their own IGP connectivity. Let’s pick one of the IPv6 from their Marseille router - 2001:5a0:d00::426e:1ce - thar1.emrs2-marseille.ipv6.as6453.net and trace towards it from Mumbai. That will help in understanding routing within their backbone.

It goes from Singapore. Interestingly Marseille > Mumbai return is direct.
Here’s very likely what is happening here:
-
Tata Comm optimised its Indian routing mostly in direction of EU > India and likely missed India > EU in IPv6 which resulted in traffic hoping via Singapore. The actual layer 1 submarine path is actually via India and hence routing is: India > Singapore > India > Marseille in the forward direction. Keep in mind India as the country has fewer datacenters serving the outside the world & hence a bit inbound heavy. Thus the majority of traffic flows are from the EU/Singapore/US towards India and not other way around.
-
The latency jump within IGP is not that significant since Singapore is close to India. We are looking here at a jump from 110ms to 148ms or so.
-
The router in Singapore has quite a different IGP metric cost for routes via Marseille in comparison to routes via US West - Los Angeles. Since we see Chiba Japan on the route, very likely it is Tata TGN Pacific cable (old name: VSNL Transpacific) - https://en.wikipedia.org/wiki/VSNL_Transpacific
Due to lower cost here, Singapore router prefers routes via their router in Los Angeles instead of Marseille.
-
Once traffic hits US West, it takes the best possible path (finally!) to reach the destination in Germany. They follow usual hot potato routing and hand off traffic to Lumen at a nearby peering point.
Source: TeleGeography
Preventing these issues
Preventing such issues is actually hard. Once the network gets large enough, deciding the IGP cost can become like a monkey balancing between latency, cost ($$$) & overall stability of the network. Take e.g Chiba, Japan - is Marseille geographically closer from there via the Indian Ocean or via the Pacific > US > Trans Atlantic route? In the same way, US West to India is better via the Pacific route and US East to India is better via the Atlantic route.
So to be fair to the Tata Comm AS6453 backbone engineering team - it’s a genuinely hard problem to ensure IGP is always optimised. The best bet here is tools that keep a close eye on the network. An alert here is possible if a tool is actively monitoring latency between loopbacks in Mumbai & Marseille as well as the routing table.
With that being said, I did send them a heads up mail informing them about this issue and hoping that latency from my Mumbai server to the Nuremberg server comes down to 130ms from 270ms!
Update - 20 April 2022
Within a few hours of my mail to the Tata Comm AS6453 NOC team, they fixed the issue.
Updated trace: Oracle Cloud Mumbai > Contabo Germany
anurag@server02 ~> mtr -wr server7.anuragbhatia.com -6
Start: 2022-04-20T22:44:55+0530
HOST: server02.bom.anuragbhatia.com Loss% Snt Last Avg Best Wrst StDev
1.|-- 2603:c000:500::8c5b:cc39 0.0% 10 0.2 0.2 0.2 0.4 0.1
2.|-- 2403:0:100::a9e 0.0% 10 1.3 1.3 1.2 2.1 0.3
3.|-- 2403:0:100::a9d 0.0% 10 1.4 1.4 1.3 1.5 0.0
4.|-- 2403::776 0.0% 10 1.6 1.7 1.6 2.0 0.1
5.|-- if-ae-1-101.tcore2.mlv-mumbai.ipv6.as6453.net 0.0% 10 1.9 1.8 1.6 1.9 0.1
6.|-- if-ae-2-2.tcore1.mlv-mumbai.ipv6.as6453.net 0.0% 10 1.7 1.7 1.7 1.7 0.0
7.|-- if-ae-5-2.tcore1.wyn-marseille.ipv6.as6453.net 0.0% 10 93.3 93.3 93.0 94.4 0.4
8.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
9.|-- if-be-1-2.ecore3.emrs2-marseille.ipv6.as6453.net 30.0% 10 93.5 93.6 93.5 93.6 0.1
10.|-- 2001:1900:5:3::279 0.0% 10 93.7 95.2 93.5 107.8 4.5
11.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
12.|-- GIGA-HOSTIN.edge8.Frankfurt1.Level3.net 0.0% 10 121.1 120.8 120.5 121.9 0.5
13.|-- server7.anuragbhatia.com 0.0% 10 118.5 120.3 118.5 133.4 4.6
anurag@server02 ~>