Event driven automation with Prometheus
Over the last few years, I have migrated my entire monitoring on Prometheus (plus Thanos). The automation code for triggering actions across my servers and network devices remains custom per project. I wanted to solve a long pending problem for home internet setup. It was to detect and act when there’s packet loss. In the past, I did that using a custom script which would test and call the REST API of the home router (Mikrotik) to make the change. It was ugly, took a while to put in place and honestly, I found it too hard to maintain. It was doing its monitoring & alerting besides Prometheus and Blackbox exporter running on the same hardware.
Prometheus + Blacbox Exporter + Alert Manager + Ansible Semaphore + Ansible Playbook
Over the weekend I deployed a rather simple system. A promql rule to check for an average of packet loss across different networks and upon detection it sends it to Alert Manager with a custom label “semaphore”.
Alertmanager has a custom receiver that points to a webhook endpoint of Ansible Semaphore. It simply calls that endpoint which triggers some rules of a pre-defined ansible playbook.
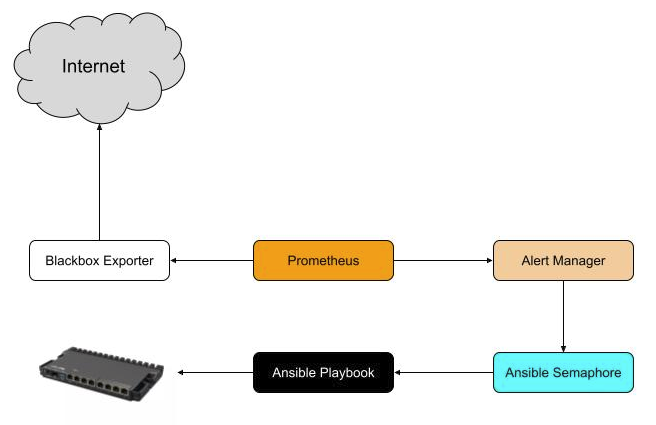
Ansible Playbook uses community.routeros.api_find_and_modify and enables certain rules in address list. The goal here is not to have Ansible write the whole config but simply flip IPs in the address list on/off to trigger a change in routing via policy-based routing.
Prometheus alert rule
- alert: Packet loss on primary ISP, ISP auto switch
expr: avg(min_over_time(probe_success{location="rtk",job="blacbox-isp1"}[1h])) <= 0.98
for: 1m
labels:
severity: warning
type: semaphore
The expr here is simply looking at an average of minimum packet loss throughout 1hr and if it’s higher than 2% rule is triggered.
Why a minimum of 1hr?
Well, it’s because of limitation that the alert manager can delay triggering of a rule (using “for”) but it cannot delay sending of “resolved”. Hence if I look at the 5-minute average and trigger the change, the rollback can happen too quickly. I want to delay rollback by an hour once there is no packet loss. So min_over_time is looking at a minimum only (not averaging it) and the of that is simply averaging all these IPs which are essentially Google, Cloudflare, Contabo, AWS and a bunch of other nodes. IPs here are selected to ensure they are distributed so that I can detect cases when there is selective packet loss on some long-haul path.
Here’s how the alert-manager config looks like:
routes:
- match:
type: semaphore
continue: true
receiver: semaphore
receivers:
- name: 'semaphore'
webhook_configs:
- url: 'https://semaphore-wekhook-endpoint' # Switch to ISP 2 when called
send_resolved: true
Logic for rollback
I wanted the system to roll back automatically. With the above rule system keeps an eye on packet loss and once packet loss has comes below the level of 2% for an hour (minimum over time…), it will trigger a send_resolved on the same endpoint. Alert Manager by design sends a JSON payload in the webhook which looks like this:
{
"status": "firing",
"labels": {
"alertname": "Packet loss on primary ISP, ISP auto switch",
"severity": "warning",
"type": "semaphore",
}
In the same way, when the issue is resolved, it sends status: “resolved”. Ansible Semaphore webhooks can be configured to receive this status and put in a variable, and same variable can be used in the ansible task.
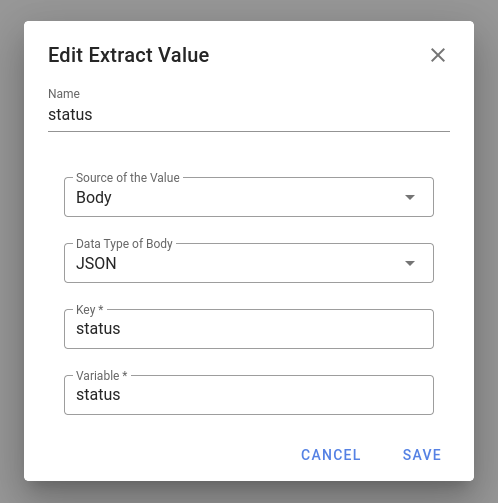
Thus I am learning the status as variable “status”. This is passed along to the playbook.
Ansible playbook sample:
- name: Move production LAN to ISP 2
community.routeros.api_find_and_modify:
hostname: "{{ hostname }}"
username: "{{ username }}"
password: "{{ password }}"
path: ip firewall address-list
find:
.id: "*7D"
values:
disabled: "no"
when: status == "firing"
- name: Move production LAN back to ISP 1
community.routeros.api_find_and_modify:
hostname: "{{ hostname }}"
username: "{{ username }}"
password: "{{ password }}"
path: ip firewall address-list
find:
.id: "*7D"
values:
disabled: "yes"
when: status == "resolved"
Overall it would be nice to have webhook trigger not mapped to specific playbook but playbook is also passed in JSON payload. That would help in keeping single endpoint/receiver for these actions. Hopefully this should take care of moving traffic and keeping the network smooth. 😀