Espresso: Google's peering edge architecture
Back in 2017 Google shared details about Espresso which is their SDN solution for scaling up their routing.
Saw this fascinating presentation from Google at SIGCOMM 2017. This blog post covers it in detail besides the talk.
Key design principles for their routing platform
-
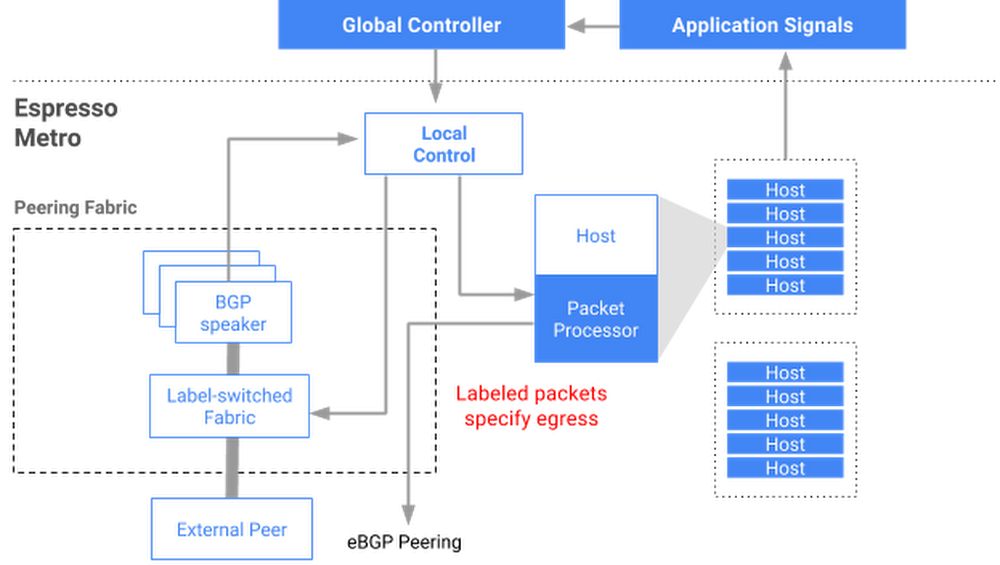
Hierarchical control plane consisting of both global as well as local control. Global takes care of overall traffic flow, inputs coming from performance metric etc while local take care of failure of BGP sessions, port/device failure etc.
-
Fail static - To ensure that any part of the system can fail and the system keeps working as it was before.
-
Software Programmability
Key features of the Espresso platform
-
Peers physically terminate on MPLS switch and BGP feature is in software and hosted on a set of a host (servers). Sessions are spread across different hosts to avoid a single point of failure. If a host fails, it will result in the failure of only a set of peering and not all. Plus, they keep backup hosts in event of failure of the primary.
-
Single BGP runs on the software, the table goes in RAM of the server giving very high scalability to hold large routing tables.
-
Google “sprays” small amounts of traffic across all available paths (non-best paths) to have a picture of all available paths and based on that data as well as inputs from applications, it selects the path.
-
This platform proves that SDN is not only for the jailed gardens and can be used for BGP routing optimisation. Many people believed SDN was for “internal network” only.
-
Back in 2017, this platform was being used for around 22% of their existing capacity and entire new buildout was using it. Now in 2020 probably number would be much higher.
The talk ended with a nice Q&A where someone asked how they know capacity on other paths because on an “unloaded path” they may see it’s all good but as soon as they send traffic it may actually choke that path. Clearly that is something which does not happen with Google peering that often and hence I must say their platform is very quick in determining and re-routing traffic.
While the presenter did not mention it in response to the question I think that due to distribution of BGP sessions across various host and carrying a large set of a table in such scalable way, they probably do not have BGP convergence issues. Also, since it’s outbound heavy, they can pick the path to send traffic. It will work in all cases where the other side is able to send traffic back to Google (TCP traffic) and their selected path is not dead.
Think about peer on the other side when you bring up your BGP session with AS15169 next time. :)
Update: 01 July 2022 author: “Anurag Bhatia” url: “/2020/04/networking/isp-column/espresso-googles-peering-edge-architecture/”
While migrating this blog to a different platform I realise that YouTube link to the talk is not valid anymore. Google has removed it for some reason.